During linux.conf.au 2008, a bunch of us ozlabbers ran the hackfest - a programming competition for conference attendees. This year's task was to optimise a fractal generation program to run on the Cell Broadband Engine - the hackfest task description is still available if you want to take a squiz.
The next few articles here will take you through a solution to the hackfest task. This is only one approach, and there may be many others. If you have any comments or questions, feel free to mail me.
(If you're viewing this through a feed reader or planet, you may want to check out the the original article, where you get much nicer code formatting.)
optimising
The task is a matter of optimising an existing program. We should take a leaf out of Knuth's book here:
"We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil."
We'll start out with something simple, and work our way up from there.
starting out
As a starting point, it'd be a good idea to check out the simple-fractal example, to find out what sort of problem we're tackling here.
While we're at it, we can do a bit of profiling on the sample fractal generator to find out where the hot paths of the program are.
A quick way to do this is to run the simple-fractal program under callgrind:
[jk@pokey simple-fractal]$ callgrind --simulate-cache=yes --dump-instr=yes \
./simple-fractal fractal.data
Looking at the callgraph output (using kcachegrind), we can get a list of the functions taking the largest amount of CPU time:
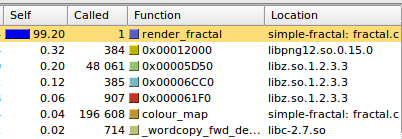
The 'Self' column gives the estimated percentage of cycles spent in each
function. We can see that 99.2% of the CPU time is spent in
render_fractal(), 0.7% in various png-encoding functions, and
0.04% calculating the colour map for the fractal.
Now that we know what we need to optimise, we can work on offloading this
to the SPEs on the Cell Processor. Because the majority of the running time is
due to render_fractal(), we should offload that work to the
SPEs.
cell version
We can get a fractal generator working on the Cell pretty quickly, by using the simple-fractal sample code for the fractal side of things, along with the data-transfer example for a framework for getting code running on the SPEs.
To me, the most logical approach is to move the render_fractal()
to the SPEs, then DMA the resulting fractal data to the PPE, which does the
PNG encoding. We should start with a simple single-SPE renderer:
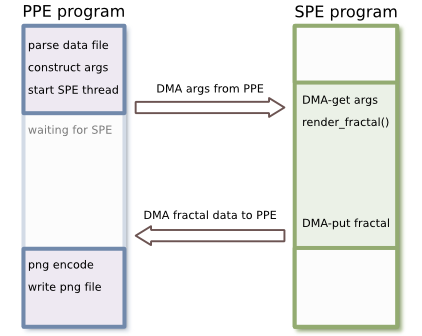
This will require a few changes:
- On the SPE side:
- We need some way of getting the fractal parameters (ie, a copy
of
struct fractal_params) to the SPE, so we should embed these intostruct spe_args:struct spe_args { struct fractal_params fractal; } __attribute__((aligned(SPE_ALIGN)));
- For the moment, we'll deal with fractals that can fit into a single
SPE DMA (ie, 16kB, which we've defined to
CHUNK_SIZE). So, we'll need a local buffer on the SPE to work with:struct pixel buf[CHUNK_SIZE / sizeof(struct pixel)] __attribute__((aligned(SPE_ALIGN)));
- As in the data-transfer example, the SPE program starts by DMA-ing a
copy of
struct spe_argsinto local store, from the address (in main memory) provided in theargvargument tomain(). We'll need to do this here too:/* * The argv argument will be populated with the address that the PPE provided, * from the 4th argument to spe_context_run() */ int main(uint64_t speid, uint64_t argv, uint64_t envp) { struct spe_args args __attribute__((aligned(SPE_ALIGN))); uint64_t ppe_buf; /* DMA the spe_args struct into the SPE. The mfc_get function * takes the following arguments, in order: * * - The local buffer pointer to DMA into * - The remote address to DMA from * - A tag (0 to 15) to assign to this DMA transaction. The tag is * later used to wait for this particular DMA to complete. * - The transfer class ID (don't worry about this one) * - The replacement class ID (don't worry about this one either) */ mfc_get(&args, argv, sizeof(args), 0, 0, 0); /* Wait for the DMA to complete - we write the tag mask with * (1 << tag), where tag is 0 in this case */ mfc_write_tag_mask(1 << 0); mfc_read_tag_status_all();
- Since the
fractal_params->imgbufpointer is a reference to main memory, we need to do a bit of shuffling to put a valid local store address in there, forrender_fractalto use. We still need to keep this pointer though, as we'll need it when we DMA our fractal (now in local store) back to main memory. So, replace theimgbufpointer with our localbufarray, and keep the PPE pointer inppe_buffor later use:/* initialise our local buffer */ ppe_buf = (uint64_t)(unsigned long)args.fractal.imgbuf; args.fractal.imgbuf = buf;
- We can now call
render_fractal()on the SPE:render_fractal(&args.fractal)
- And finally, DMA-put our rendered fractal to main memory, at the original
ppe_bufpointer, and return:mfc_put(args.fractal.imgbuf, ppe_buf, args.fractal.rows * args.fractal.cols * sizeof(struct pixel), 0, 0, 0); /* Wait for the DMA to complete */ mfc_write_tag_mask(1 << 0); mfc_read_tag_status_all(); return 0; }
- We need some way of getting the fractal parameters (ie, a copy
of
- On the PPE side:
- Since we're creating a SPE thread, we need a function to do the
spe_context_run(), to pass topthread_create:void *spethread_fn(void *data) { struct spe_thread *spethread = data; uint32_t entry = SPE_DEFAULT_ENTRY; /* run the context, passing the address of our args structure to * the 'argv' argument to main() */ spe_context_run(spethread->ctx, &entry, 0, &spethread->args, NULL, NULL); return NULL; }
- We need to be careful with the alignment of the fractal buffer, as
the SPE needs to DMA the fractal here. So, instead of using
malloc, usememalign/* allocate our image buffer */ fractal->imgbuf = memalign(SPE_ALIGN, sizeof(*fractal->imgbuf) * fractal->rows * fractal->cols);
- Copy the parsed fractal data into the
spe_argsstructure:memcpy(&thread.args.fractal, fractal, sizeof(*fractal));
- Rather than calling render_fractal on the PPE, we just create the SPE
context, upload the SPE program and start it in a new thread:
thread.ctx = spe_context_create(0, NULL); spe_program_load(thread.ctx, &spe_fractal); pthread_create(&thread.pthread, NULL, spethread_fn, &thread);
- Now the SPE should be happily generating the fractal, and will DMA it
back to our allocated buffer when it's complete. We just wait for the SPE
thread to finish, and write the fractal out to a PNG file:
pthread_join(thread.pthread, NULL); /* compress and write to outfile */ if (write_png(outfile, fractal->rows, fractal->cols, fractal->imgbuf)) return EXIT_FAILURE; return EXIT_SUCCESS; }
- Since we're creating a SPE thread, we need a function to do the
If immediate gratification is more your style, here's one I prepared earlier.
After these changes (plus some general plumbing), you should have a working SPE-based fractal renderer!

However, we still have a few limitations:
- We can only generate fractals up to 16kB in total size - that's a maximum of 64 × 64 pixels;
- We've only started one SPE thread; and
- The generation is not significantly quicker on the SPE than on the PPE.
So, nothing too exciting yet. However, in the next part of this series, we'll be working on optimising our new program to use some of the neat features of the Cell architecture, and get around each of these limitations.
Stay tuned!
OK. Yeah, great read for a useful intro to Cell hacking. :)