The linux.conf.au 2008 hackfest is closed now, but this page remains as a little information about Cell/B.E. programming.

IBM LTC OzLabs proudly presents the linux.conf.au 2008 hackfest
The Task
The task for this year's hackfest is to write a program to render fractals in the least amount of time. Your program will be benchmarked on a Cell Broadband Engine processor, so you will probably need to use the special features of the Cell/B.E. to make your program as fast as possible.
The Program
By default, your program will read a set of parameters in a file
called fractal.data, and output the corresponding fractal
as fractal.png. However, these defaults are controlled by a set
of command-line arguments - see the specification
section.
The input file is a simple 'name = value' format. We suggest that you
use the parse_fractal() function from parse-fractal.c example to parse
the input file into fractal parameters.
The output fractal will need to be png-encoded, but we have provided
a simple function (write_png() in png.c) for you to use.
Specfication
Your program should take the following optional arguments:
- -p <paramsfile>
- Specifies a file to read the fractal parameters from, defaults to
fractal.data - -o <outfile>
- Specifies where the output png fractal should be saved, defaults to
fractal.png - -n <number-of-spe-threads>
- Number of SPE threads to use, defaults to 1
We will be testing your entry with a number of different fractals, but you may make the following assumptions:
- The number of rows will be evenly divisible by the number of SPE threads
- The number of columns * 4 will be divisible by 16 (this means you don't have to worry too much about dividing the rows into DMA-able parts).
- The entire fractal image will be smaller than the available system memory.
Judging
Your program will be tested on a Cell machine. A range of fractal parameters will be used, as well as a varying number of SPE threads.
We will benchmark your program by running it with time. The
winning program will be the one that renders the sample fractals correctly,
in the least amount of time. However, the judges reserve the right to
apply time penalties/bonuses for particularly outstanding entries (eg,
don't just try to circumvent the 'time' command!)
We won't be worrying too much about the polish of the code - a missing free() won't lose you points. However, we need to be able to read your entry clearly.
The judges' decision is final.
Licensing
Your entry should be licensed under the GPL, either version 2 or 3.
The code samples given in this excercise are made available under the GPL version 3
Suggested steps
- Check out the documentation on the rest of this page. You'll need to understand a little about fractals, and a little more about the Cell/B.E. architecture.
- Get a Cell development environment set up for yourself.
- Compile the Hello World and Parallel Hello World examples, and take a look at the code required to run the SPE program
- Take a look at the data-transfer example, and get that running
- Grab the
fractal-templatetarball to use a basis for your entry - Alter the template to generate fractals on the SPEs before sending the data back to the PPE. Make the fractals small enough to fit into a single DMA (per SPE) at this stage.
- Extend your code to allow fractals bigger that a single DMA.
- Optimise!
Fractals
We'll be generating fractal images based on the Mandelbrot set. To test whether a complex number C is part of the Mandelbrot set, we iterate with the following rules:
Z0 = 0 + 0i
Zi = Z(i - 1)2 + C
After a number (i) of iterations, either Z will converge to a small number,
or approach infinity:
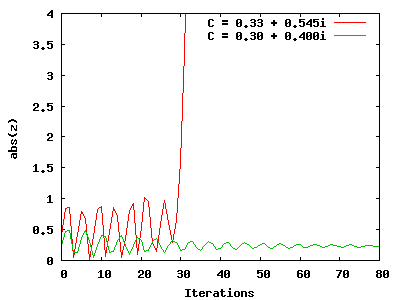 If the number converges, it is considered to be within the Mandelbrot set.
By mapping the values of C to a 2D set of pixels (real components on the
x-axis, imaginary components on the y-axis), we can make images like the
one at the top of this page. Each pixel is coloured by the number of
iterations taken for Z to approach infinity: darker colours represent a
smaller number of iterations.
If the number converges, it is considered to be within the Mandelbrot set.
By mapping the values of C to a 2D set of pixels (real components on the
x-axis, imaginary components on the y-axis), we can make images like the
one at the top of this page. Each pixel is coloured by the number of
iterations taken for Z to approach infinity: darker colours represent a
smaller number of iterations.
However, for this exercise, we have provided a sample fractal
implementation for you to base your entry on. The simple-fractal program will generate
a fractal, using the render_fractal() function in fractal.c.
The important part of this program is the render_fractal()
function. Given a structure of fractal parameters:
struct fractal_params: defines a fractal to generate
struct fractal_params { /* the number of rows and columns in the resulting image, in pixels */ int cols, rows; /* the cartesian coordinates of the center of the image */ float x, y; /* per-pixel increment of x and y */ float delta; /* maximum number of iterations to test */ int i_max; /* the image: an array of rows * cols elements of struct pixels */ struct pixel *imgbuf; };
it calculates the i value at each pixel, and colours the pixel accordingly:
Fractal rendering code
void render_fractal(struct fractal_params *params) { int i, x, y; /* complex numbers: c and z*/ float cr, ci, zr, zi; float x_min, y_min, tmp; x_min = params->x - (params->delta * params->cols / 2); y_min = params->y - (params->delta * params->rows / 2); for (y = 0; y < params->rows; y++) { ci = y_min + y * params->delta; for (x = 0; x < params->cols; x++) { cr = x_min + x * params->delta; zr = 0; zi = 0; for (i = 0; i < params->i_max; i++) { /* z = z^2 + c */ tmp = zr*zr - zi*zi + cr; zi = 2.0 * zr * zi + ci; zr = tmp; /* if abs(z) > 2.0 */ if (zr*zr + zi*zi > 4.0) break; } colour_map(¶ms->imgbuf[y * params->cols + x], i, params->i_max); } } }
Colouring
The colour_map() function takes the i and i_max values,
and populates the current pixel with a colour. We just use a straightforward
HSV to RGB transformation, using i as the hue value:
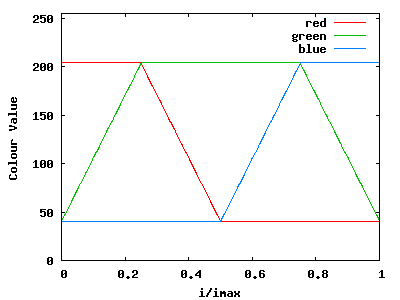
You don't need to use the exact colour-map function, but
your fractal does need to be coloured in the same way (ie, starting at
red for small values of i, moving through green, then to
blue for values approaching i_max).
Example code
The simple-fractal source code is in the simple-fractal.tar.gz sample.
Writing applications for Cell
We don't expect you to have any prior experience of Cell programming, we've provided some documentation and sample code.
Cell Architecture 101
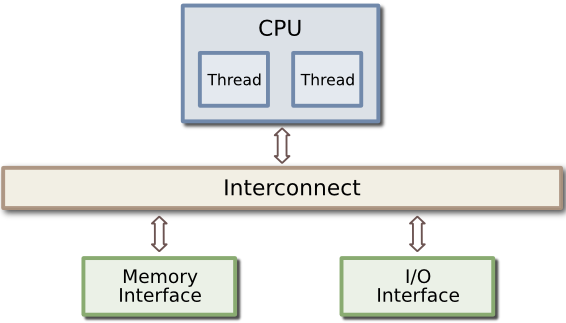
Cell processors are similar to other systems, except that:
- The CPU is now called a PPE
- There are a number of smaller processors (called Synergistic Processing Elements, or SPEs), on the processor die.
| Standard CPU | Cell CPU |
|---|---|
 |
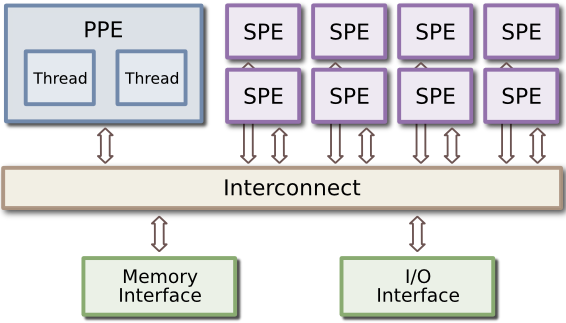 |
These SPEs are fairly independent from the main processor - they have their own memory (called 'Local Store'). Typically, the SPEs work on data in the Local Store memory, transferring to and from main memory as necessary. Think of the SPEs as "offload processors".
The tricky part is that you need to program the SPEs yourself - this means compiling a binary for the SPE (using a special build of gcc), and having your main program upload and run this binary.
However, the good news is that you can do this with just a few function calls - take a look at our first sample code:
SPE 'Hello World'
We have to start with a 'Hello World' app, right? Here's a SPE version of the classic Hello World program:
Hello World: SPE-side code
#include <stdio.h> int main(void) { printf("hello world!\n"); return 0; }
Pretty unspectacular, huh?
The problem is that if we compile this, it isn't automatically run on the SPEs for us. We need a bit of 'wrapper code' to run on the main processor, which uploads this (compiled) code to a SPE, then runs it.
Hello World: PPE-side code
#include <stdint.h> #include <libspe.h> /* A 'handle' to the compiled SPE program. This variable is created by * the 'embedspu' tool, but just think of it as a program that can be * run on an SPE. */ extern spe_program_handle_t spe_hello_world; int main(void) { spe_context_ptr_t ctx; uint32_t entry = SPE_DEFAULT_ENTRY; /* create a SPE context - the SPE eqivalent of a normal process */ ctx = spe_context_create(0, NULL); /* load the 'spe_hello_world' program into our context */ spe_program_load(ctx, &spe_hello_world); /* run the context */ spe_context_run(ctx, &entry, 0, NULL, NULL, NULL); return 0; }
Download the spe-hello-world.tar.gz example sources (also includes the parallel example).
Parallel SPE Hello World
In the above listing, the spe_context_run() blocks while
the SPE code is running. To parallelise your program, just use the
pthreads library; the hello-world-parallel.c
example shows how to create multiple SPE threads that run at once.
The main differences between the serial and parallel versions:
- We have a new struct (
spe_thread) to contain the spe context and pthread data:struct spe_thread { spe_context_ptr_t ctx; pthread_t pthread; };
- We have a new function to perform the spe_context_run().
void *spethread_fn(void *data) { struct spe_thread *spethread = data; uint32_t entry = SPE_DEFAULT_ENTRY; /* run the context */ spe_context_run(spethread->ctx, &entry, 0, NULL, NULL, NULL); return NULL; }
- We have a loop that creates
n_threadscontexts, uploads thespe_hello_worldprogram, then creates a new thread. This new thread is configured to call the newspethread_fnfunction:for (i = 0; i < n_threads; i++) { threads[i].ctx = spe_context_create(0, NULL); spe_program_load(threads[i].ctx, &spe_hello_world); /* run the context in a new thread, passing the spe_thread * struct as the first argument of spethread_fn */ pthread_create(&threads[i].pthread, NULL, spethread_fn, &threads[i]); }
Transferring Data
In order to write useful programs, we need to be able to share data between the PPE and the SPEs. To do this, the SPEs can copy blocks of data between the main memory and their own internal memory (called "Local Store").
The data-transfer sample code demonstrates the use of "SPE DMAs" to transfer data between the PPE and the SPEs. This sample implements memset on the SPEs: the PPE sends the memset parameters (buffer address, buffer size, and a byte value) to the SPE, then the SPE sets the buffer to the specified byte value, by DMAing data over to the PPE buffer.
Some notes on the data-transfer example:
- We need to pass a set of arguments to the SPE program: the PPE buffer
address, the PPE buffer size, and the byte to copy into this buffer. To
do this, we define a
spe_argsstruct:struct spe_args { uint64_t buf_addr; uint32_t buf_size; char c; };
- After populating this struct, we pass its address to the SPE, by
providing it to argument 4 of
spe_context_run():spe_context_run(spethread->ctx, &entry, 0, &args, NULL, NULL);
- The SPE will see this address passed as the second argument
(
argv) to itsmain()function. We then copy the struct into SPE Local Store by using themfc_get()function:int main(uint64_t speid, uint64_t argv, uint64_t envp) { struct spe_args args __attribute__((aligned(SPE_ALIGN))); /* DMA the spe_args struct into the SPE. The mfc_get function * takes the following arguments, in order: * * - The local buffer pointer to DMA into * - The remote address to DMA from * - A tag (0 to 15) to assign to this DMA transaction. The tag is * later used to wait for this particular DMA to complete. * - The transfer class ID (don't worry about this one) * - The replacement class ID (don't worry about this one either) */ mfc_get(&args, argv, sizeof(args), 0, 0, 0);
- On the Cell, DMAs are asynchronous - the DMA happens in the
background, so the SPE can keep doing other stuff while the data is
being transferred. So, we need to wait for that DMA to complete before
accessing the struct:
/* Wait for the DMA to complete - we write the tag mask with * (1 << tag), where tag is 0 in this case */ mfc_write_tag_mask(1 << 0); mfc_read_tag_status_all();
The data transfer takes two arguments - the number of SPE threads to run,
and the buffer size. It writes a file (out.data) to the
current directory. Each SPE will fill its portion of the buffer with
it's index (ie, 1 to n_threads).
Restrictions on DMAs
The DMA engines in the SPEs are a bit fussy:
- The MFC supports DMA transfer sizes of 1, 2, 4, 8, 16 or a multiple of 16 bytes.
- The source and destination addresses must be naturally aligned - eg, a 4-byte transfer must be 4-byte aligned.
- A single DMA can transfer up to 16kB.
If your program receives a SIGBUS signal, it's probably due to a DMA of an invalid size, or improper alignment.
See section 19.2.1 of the Cell/B.E. Programming Handbook for more information on DMAs.
Download the data-transfer.tar.gz example sources.
Optimising your program
Once you have a working fractal generator, you'll need to get it going as fast as possible. Here are some tips:
Parallelise
The current Cell/B.E. processors have 8 SPEs per chip (however, when running on a PS3, only 6 are available), so you can get a substantial speedup by dividing the computation into parts, and getting each SPE to work on a separate part of the fractal
Use the SPE vector capabilities
The SPEs of the Cell/B.E. have an instruction set almost entirely composed of SIMD instructions - so you can do most computations on four operands at a time.
To take advantage of these SIMD capabilities, you can use "vector" types in your code.
For example, consider a simple function to multiply a number by three:
multiply_by_three, scalar version
float multiply_by_three(float f) { return f * 3; }
By vectorising this function, we can do four operations in the same amount of time:
multiply_by_three, vector version
vector float multiply_by_three(vector float f); { return f * (vector float){3, 3, 3, 3}; }
The vector float type is similar to an array of 4
floats, except that we can operate on the vector as a whole.
If we look at the instructions generated for both the scalar and vector versions of the multiply_by_three function, they're exactly the same:
Assembly implementation of multiply_by_three(), both vector and scalar versions. Function argument is in register 3, return value is placed in register 3.
multiply_by_three: ilhu $2,16448 ; load {3, 3, 3, 3} into register 2 fm $3,$3,$2 ; register 3 = (register 3) * (register 2) bi $lr ; return to caller
So, if you're using scalar operations, we get one multiply in three instructions. Using the vector equivalent, we get four multiplies in three instructions.
Use DMAs efficiently
The DMA engines in the SPEs actually work on 128-byte blocks. If you align your buffers on 128-byte boundaries, you'll get increased bandwidth between SPEs and memory.
Also, since the DMAs are asynchronous, you can keep computing the fractal while a DMA is occuring. Also, you can have multiple DMAs (up to 15) in flight at any one time, just use a different tag for each. However, you need to make sure that the DMA is complete before accessing (for a mfc_get) or overwriting (for a mfc_put) the data!
Make your code SPU-friendly
The SPEs are fairly simple processors - they don't have as many advanced features (such as branch prediction) as a standard CPU. Here are some hints to keep you code running fast on an SPE:
- The SPEs are great for running linear code, but aren't so good with
branches. Avoid lots of
ifstatements, if possible.
Cell Documentation
The IBM developerworks site has a good collection of Cell Documentation. The following documents will be of particular help:
- Cell Broadband Engine Architecture Specification - the definition of the Cell Architecture
- C/C++ Language Extensions for Cell Broadband Engine Architecture -
specification for the SPE-specific C function calls (eg
mfc_get) - Cell/B.E. Programming Handbook - general Cell Programming Guide
- SPE Runtime Management Library API the reference for libspe2
- SPU Assembly Language Specification
- SPU Instruction Set Architecture - defines the instruction set available on the SPEs
The following may also be helpful:
- Slides from The Cell Programming Workshop at Georgia Tech
Cell Development Tools
Unless you've written Cell applications before, you'll probably need to get a build environment set up.
Some distributions have packages available for Cell development - you'll probably need the following:
- libspe2
- spu-binutils
- spu-gcc
- spu-newlib
You can just use a standard PowerPC compiler for the PPE code, but if you don't have one available, you may also need:
- ppu-binutils
- ppu-gcc
Finally, if you'd like a 'sysroot image' (ie, headers and libraries
built for the Cell machines, in /opt/cell, install the
ppu-sysroot package. This is especially handy if you're
cross-compiling from an x86 machine.
IBM has released a Cell Software Development kit - containing libraries, compilers, documentation and a Cell simulator. This SDK is distributed as a set of RPMs, based on RHEL or Fedora. If you like doing things the official way, you can download the Cell SDK from the Barcelona Supercomputing Center site.
Building from source
If you'd prefer to build a cell toolchain from source, check out the cell toolchain building instructions. This will probably take some time and tinkering, so only do this as a last resort.