In the last article we finished with a SPE-based fractal renderer, but with a limited maximum fractal size of 64 × 64 pixels:

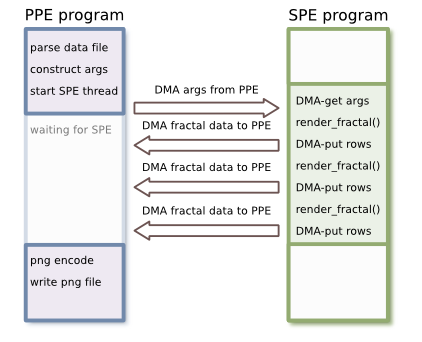
We'd like to generate full-size fractals, but the DMAs (which we use to transfer the fractal image out of the SPE) have a maximum size of 64kB. The solution is to perform multiple DMAs each containing a subset of the image's rows.
Each invocation of render_fractal() should render a DMA-able
chunk of fractal data, then we perform the DMA. We do this until the SPE has
processed the entire image:
We just need to modify the spe-fractal code (spe-fractal.c) a
little. At present, we just render the whole fractal in one pass and DMA the
data in the main() function:
render_fractal(&args.fractal); mfc_put(args.fractal.imgbuf, ppe_buf, args.fractal.rows * args.fractal.cols * sizeof(struct pixel), 0, 0, 0); /* Wait for the DMA to complete */ mfc_write_tag_mask(1 << 0); mfc_read_tag_status_all();
First, we need to modify our render_fractal() fuction to take
a starting row, and a number of rows to render. This is the new prototype
of render_fractal():
static void render_fractal(struct fractal_params *params, int start_row, int n_rows)
In the SPE program's main(), we just need to set up some
convenience variables:
bytes_per_row = sizeof(*buf) * args.fractal.cols; rows_per_dma = sizeof(buf) / bytes_per_row;
And do the rendering and DMAs in a loop:
for (row = 0; row < args.fractal.rows; row += rows_per_dma) { render_fractal(&args.fractal, row, rows_per_dma); mfc_put(buf, ppe_buf + row * bytes_per_dma, rows_per_dma * bytes_per_row, 0, 0, 0); /* Wait for the DMA to complete */ mfc_write_tag_mask(1 << 0); mfc_read_tag_status_all(); }
This loop will render as many image rows as will fit into a single DMA, then DMA the rendered data back to main memory.
Now, we're able to render fractals larger than 64 × 64 pixels:

The source for the updated fractal renderer is available in fractal.2.tar.gz.
performance
Now that we can generate full-size fractals, we can compare the running times with the PPE-based fractal renderer. The following table shows running times with a standard fractal (using these fractal parameters).
| Implementation | Time (sec) |
|---|---|
| PPE | 55.7 |
| 1 SPE | 40.7 |
So, we get a 27% speedup by moving the fractal generation code to run on a SPE. We're still a way behind the optimal performance though, and benchmarking on other systems gives better times (for example, generating the same fractal on an Intel Core 2 Duo @ 2.4GHz takes 13.8 seconds).
We can improve the Cell performance by a large amount - stay tuned for the next article to see how.