In part two of this series, we had just ported a fractal renderer to the SPEs on a Cell Broadband Engine machine. Now we're going to start the optimisation...
Our baseline performance is 40.7 seconds to generate the sample fractal (using the sample fractal parameters).
The initial SPE-based fractal renderer used only one SPE. However, we have more available:
| Machine | SPEs available |
|---|---|
| Sony Playstation 3 | 6 |
| IBM QS21 / QS22 blades. | 16 (8 per CPU) |
So, we should be able to get better performance by distributing the render work between the SPEs. We can do this by dividing the fractal into a set of n strips, where n is the number of SPEs available. Then, each SPE renders its own strip of the fractal.
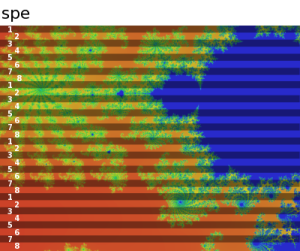
The following image shows the standard fractal, as would be rendered by 8 SPEs, with shading to show the division of the work amongst the SPEs.

In order to split up the work, we first need to tell each SPE which part of
the fractal it is to render. We'll add two variables to the
spe_args structure (which is passed to the SPE during program
setup), to provide the total number of threads (n_threads) and
the index of this SPE thread (thread_idx).
struct spe_args { struct fractal_params fractal; int n_threads; int thread_idx; };
spe changes
On the SPE side, we use these parameters to alter the invocations of
render_fractal. We set up another couple of convenience variables:
rows_per_spe = args.fractal.rows / args.n_threads; start_row = rows_per_spe * args.thread_idx;
And just alter our for-loop to only render
rows_per_spe rows, rather than the entire fractal:
for (row = 0; row < rows_per_spe; row += rows_per_dma) { render_fractal(&args.fractal, start_row + row, rows_per_dma); mfc_put(buf, ppe_buf + (start_row + row) * bytes_per_row, bytes_per_row * rows_per_dma, 0, 0, 0); /* Wait for the DMA to complete */ mfc_write_tag_mask(1 << 0); }
ppe changes
The changes to the PPE code are fairly simple - instead of just creating one thread, create n threads.
First though, let's add a '-n' argument to the program to
specify the number of threads to start:
while ((opt = getopt(argc, argv, "p:o:n:")) != -1) { switch (opt) { /* other options omitted */ case 'n': n_threads = atoi(optarg); break;
Rather than just creating one SPE thread, we create n_threads.
Also, we have to set the thread-specific arguments for each thread:
for (i = 0; i < n_threads; i++) { /* copy the fractal data into this thread's args */ memcpy(&threads[i].args.fractal, fractal, sizeof(*fractal)); /* set thread-specific arguments */ threads[i].args.n_threads = n_threads; threads[i].args.thread_idx = i; threads[i].ctx = spe_context_create(0, NULL); spe_program_load(threads[i].ctx, &spe_fractal); pthread_create(&threads[i].pthread, NULL, spethread_fn, &threads[i]); }
Now, the SPEs should be running, and generating their own slice of the fractal. We just have to wait for them all to finish:
/* wait for the threads to finish */ for (i = 0; i < n_threads; i++) pthread_join(threads[i].pthread, NULL);
If you're after the source code for the multi-threaded SPE fractal renderer, it's available in fractal.3.tar.gz.
That's it! Now we have a multi-threaded SPE application to do the fractal rendering. In theory, an n threaded program will take 1/n of the time of a single-threaded implementation, let's see how that fares with reality...
performance
Let's compare invocations of our multi-threaded fractal renderer, with
different values for the n_threads parameter.
| SPE threads | Running time (sec) |
|---|---|
| 1 | 40.72 |
| 2 | 30.14 |
| 4 | 18.84 |
| 6 | 12.72 |
| 8 | 10.89 |
Not too bad, but we're definitely not seeing linear scalability here; we could expect the 8 SPE case to take around 5 seconds, rather than 11.
what's slowing us down?
A little investigation into the fractal generator will show that some SPE
threads are finishing long before others. This is due to the variability in
calculation time between pixels. In order to see if a point (ie, pixel) in the
fractal does not converge towards infinity (and gets coloured blue),
we need to do the full i_max tests in render_fractal
(i_max is 10,000 in our sample fractal). Other pixels may
converge much more quickly (possibly in under 10 iterations), and so are orders
of mangitude faster to calculate.
We end up with slices that are very quick to calculate, and others that take longer. Of course, we have to wait for the longest-running SPE thread to complete, so our overall runtime will be that of the slowest thread.
So, let's take another aproach to distributing the workload. Rather than dividing the fractal into contiguous slices, we can interleave the SPE work. For example, if we were to use 2 SPE threads, then thread 0 would render all the even chunks, and thread 1 would render all the odd chunks (where a "chunk" is a set of rows that fit into a single DMA). This should even-out the work between SPE threads.
This is just a matter of changing the SPE for-loop a little.
Rather than the current code, which divides the work into
n_threads contiguous chunks:
for (row = 0; row < rows_per_spe; row += rows_per_dma) { render_fractal(&args.fractal, start_row + row, rows_per_dma); mfc_put(buf, ppe_buf + (start_row + row) * bytes_per_row, bytes_per_row * rows_per_dma, 0, 0, 0); /* Wait for the DMA to complete */ mfc_write_tag_mask(1 << 0); mfc_read_tag_status_all(); }
We change this to render every n_threadth
chunk, starting from thread_idx, which gives us the
the interleaved pattern:
for (row = rows_per_dma * args.thread_idx; row < args.fractal.rows; row += rows_per_dma * args.n_threads) { render_fractal(&args.fractal, row, rows_per_dma); mfc_put(buf, ppe_buf + row * bytes_per_row, bytes_per_row * rows_per_dma, 0, 0, 0); /* Wait for the DMA to complete */ mfc_write_tag_mask(1 << 0); mfc_read_tag_status_all(); }
An updated renderer is available in fractal.4.tar.gz.
Making this small change gives some better performance figures:
| SPE threads | Running time (sec) |
|---|---|
| 1 | 40.72 |
| 2 | 20.75 |
| 4 | 10.78 |
| 6 | 7.44 |
| 8 | 5.81 |
We're doing much better now, but we're still nowhere near the theoretical maximum performance of the SPEs. More optimisations in the next article...